運用保守とは?仕事内容・運用と保守の違いをSaaS担当者向けに完全解説
「運用保守ってどこまでが運用で、どこからが保守なの?」担当者が最初にぶつかるこの疑問に答えながら、SaaS開発現場で実践できる業務効率化の7ポイントを解説します。役割分担の明確化からインシデント対応・ナレッジ共有まで、属人化を防ぐ具体的な手順書テンプレートも紹介しています。

「運用と保守、どちらが対応すべきか」——障害発生時にこの判断が遅れると、SaaSビジネスでは顧客の解約に直結します。しかし、運用保守の役割境界を正しく理解できている担当者は少なく、属人化・ドキュメント不整備・エスカレーション遅延という三重苦に悩む現場は後を絶ちません。
運用保守とは?(30秒でわかる結論)
- 運用保守 とは、リリース済みのシステムを安定稼働させ続けるための業務全般を指し、ITサービスマネジメントの国際的フレームワーク ITIL 4 では「サービスの提供と継続的な改善」として整理されています。
- 運用 =サーバー監視・バックアップ・アカウント管理など「日々の正常状態を維持する定常業務」
- 保守 =バグ修正・セキュリティパッチ・機能改修など「システム自体に手を加える非定常業務」
- 運用保守エンジニアの主な仕事内容 は、監視・障害一次対応・エスカレーション・ドキュメント整備・改善サイクルの 5 領域。SaaS では特に MTTR(平均復旧時間)の短縮 が最重要 KPI となります。
本記事では、 運用保守の基本概念と仕事内容の違い を整理したうえで、SaaS開発チームがすぐに導入できる 業務効率化の7つのポイント を、ITIL 4・IPA・Google SRE などの一次ソースを参照しながら実例とともに解説します。運用保守エンジニアとしてスキルアップを目指す方にも、チームの体制を整備したいマネージャーにも役立つ内容です。
運用と保守の役割分担を明確にする
運用保守とは、システムを安定稼働させるための「運用」と、トラブル対応や機能改修を行う「保守」を組み合わせた業務です。SaaS開発において、この2つの役割を明確に切り分けることが効率化の第一歩となります。
ITIL 4 では、運用保守を含む IT サービスマネジメント全体を「組織と人材/情報と技術/パートナとサプライヤ/バリューストリームとプロセス」の 4 つの側面 で捉えるべきだと整理しています。属人的な役割分担ではなく、組織横断のプロセスとして設計することが重要です。
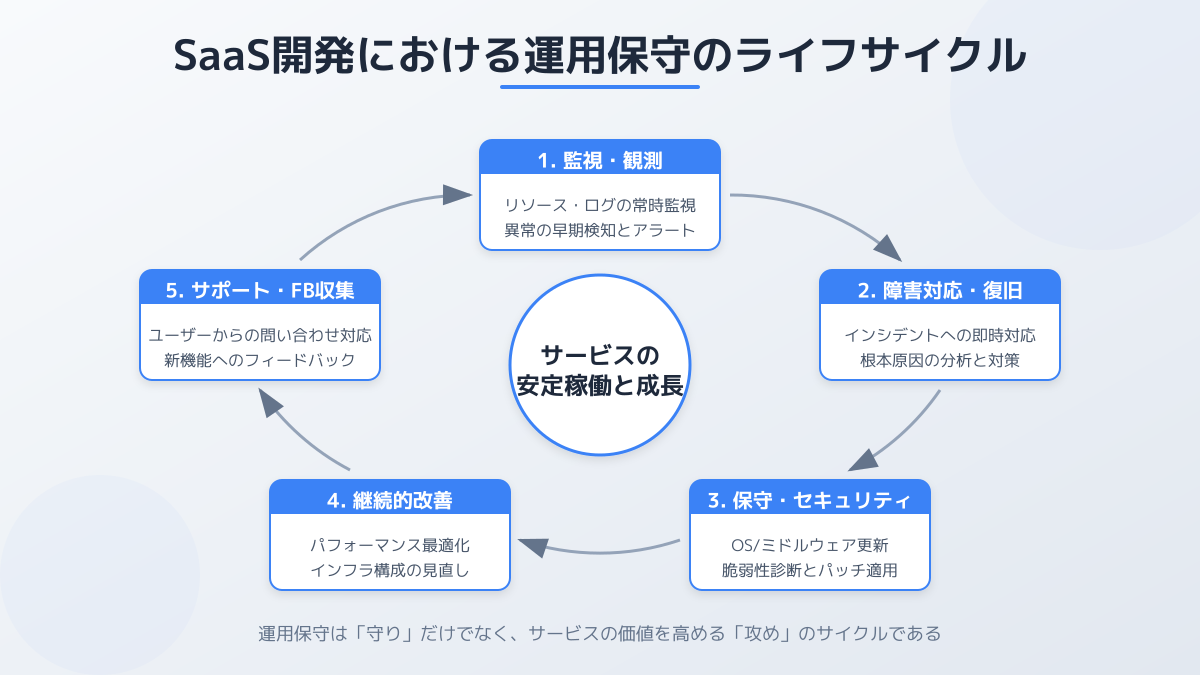
運用と保守の役割分担と判断基準
運用は、日々のサーバー監視やデータバックアップなど、システムを正常な状態に維持する定常業務を指します。一方、保守はバグ修正やセキュリティアップデートなど、システム自体に手を加える非定常業務です。
現場でこれらを混同すると、障害発生時の責任の所在が曖昧になり、復旧が遅れる原因となります。日本でも IPA(独立行政法人 情報処理推進機構)が公開する「デジタル・ガバメント推進標準ガイドライン 実践ガイドブック(第3編第9章 運用及び保守)」で、運用と保守の責任分界・KGI/KPI 設定・エビデンス収集を明確化することが推奨されています。
そのため、どこまでが運用チームの管轄で、どのような事象が発生したら開発チームへエスカレーションするのか、対応の判断基準を具体的にマニュアル化しておく必要があります。
現場での運用と顧客対応の注意点
運用保守を現場で実践する際の注意点は、単にシステムを監視するだけでなく、顧客の業務影響を最小限に抑える視点を持つことです。SaaSビジネスにおいて、障害対応の遅れは解約に直結します。異常を検知した際は、ユーザーへの迅速なアナウンス体制を整えることが求められます。
また、顧客の不満を事前に察知し、システムの改善に繋げるためには、サポート部門との連携も不可欠です。顧客対応の役割分担については、 カスタマーサクセスと営業の違いとは?役割や目標設定など8つのポイントで完全解説 を参考に体制を構築してください。
運用保守の仕事内容を正確に切り分ける
SaaS開発において、運用と保守は混同されがちですが、両者の役割は明確に異なります。安定したサービス提供を続けるためには、それぞれの目的を理解し、運用保守における仕事内容を正確に切り分けることが重要です。
ここでは、運用と保守の役割や目的、主な仕事内容を比較表で整理します。
| 項目 | 運用 | 保守 |
|---|---|---|
| 役割 | システムを日常的に稼働させ、正常な状態を維持する | システムの障害対応や、改修・アップデートを行う |
| 目的 | サービスの安定提供、ユーザーの利便性確保 | 課題の根本解決、システムの品質向上と陳腐化防止 |
| 主な業務内容 | サーバー監視、データバックアップ、アカウント管理、ヘルプデスク対応 | バグ修正、セキュリティパッチ適用、新機能の追加、仕様変更 |
| 主要 KPI | 稼働率(例 99.9%)、MTBF(平均故障間隔) | MTTR(平均復旧時間)、変更失敗率 |
稼働率の設計や許容停止時間の決め方は、SaaS 契約の文脈で読むとさらに理解が深まります。発注側の視点は SLAとは?SaaS契約で発注側が確認すべき7つのポイント【稼働率・ペナルティ計算付き】 でまとめています。
定常業務と非定常業務の境界線
現場で運用保守体制を構築する際の判断ポイントは、定常業務と非定常業務の境界線をどこに引くかです。マニュアル化できる監視やバックアップなどの定常業務は運用チームが担い、コードの修正やインフラの構成変更を伴う非定常業務は保守チーム(または開発チーム)が担うという明確な基準を設けます。
注意点として、両チーム間の連携不足が挙げられます。障害発生時に「どちらが対応するか」で初動が遅れないよう、エスカレーションのフローと責任の所在を事前に定義しておく必要があります。
また、SaaS事業の立ち上げ期からこれらの体制を想定しておくことで、サービス拡大時の運用負荷を軽減できます。事業計画の段階から運用体制を含めた全体像を描き、決裁者へ提案する際は、【実例あり】新規事業の企画書の作り方とプレゼン資料例|決裁を通す立ち上げプロセス7ステップ を活用して社内の合意形成を図るのも有効な手段です。
障害発生時のエスカレーション体制を構築する
運用保守を効率化する3つ目のポイントは、障害発生時の対応フローとエスカレーション体制を明確に構築することです。システム障害は、どれほど事前に対策を講じても完全にゼロにすることはできません。そのため、いかに迅速に異常を検知し、適切な担当者へ情報を引き継いで復旧させるかが、サービスの信頼性を大きく左右します。
Google が公開している「Site Reliability Engineering(SRE)」では、可用性 99.9% などの目標値を達成したあとは、 MTBF(故障を起こさない時間)を伸ばすことより、MTTR(復旧時間)を短くする "fast fix" を優先する という考え方が示されています。SaaS のように障害が必然である前提に立つなら、「壊さない努力」よりも「壊れても早く戻す」体制づくりに投資した方が ROI が高いのです。
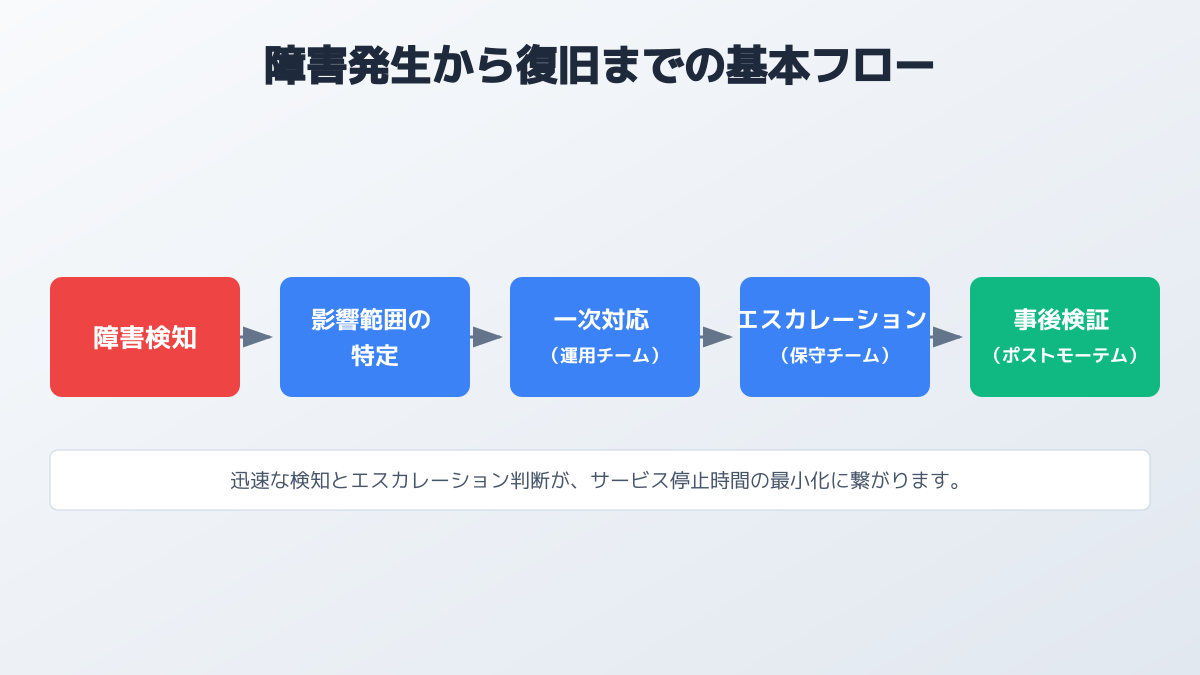
影響範囲と深刻度に基づく対応
現場で対応を行う際の判断ポイントは、障害の影響範囲と深刻度に基づく優先順位付けです。全ユーザーの業務が停止するようなクリティカルな障害と、特定の条件下でのみ発生する軽微な不具合とでは、対応スピードや連絡経路を明確に分ける必要があります。
運用時の注意点として、対応手順が特定のエンジニアに依存する 属人化 を防ぐことが挙げられます。誰が一次対応にあたっても一定の品質を保てるよう、対応マニュアルや連絡網を常に最新の状態に維持してください。
また、障害が収束した後は必ず ポストモーテム(事後検証) を実施することが重要です。根本原因の特定と再発防止策をチーム全体で共有することで、運用保守の品質を持続的に向上させることができます。
手順化しやすい業務から標準化を進める
SaaS開発における運用保守を効率化する4つ目のポイントは、業務の属人化を排除し、チーム全体で対応できる体制を構築することです。システムが拡大し機能が複雑化するにつれて、特定の運用保守エンジニアに知識やノウハウが偏ることは、事業継続における大きなリスクとなります。
属人化を解消するための判断ポイントは、頻発するアラート対応や定型的な復旧作業など、手順化しやすい業務から優先的に標準化を進めることです。すべての作業を一度にマニュアル化しようとすると現場の負担が過大になるため、発生頻度が高く、かつ手順が明確なものから段階的に着手します。
現場で運用保守の体制を整備する際の注意点として、ドキュメントの更新作業を日々の業務フローに組み込むことが挙げられます。障害対応が終わった直後の振り返りの段階で、手順書の追記や修正をセットで行うルールを設けることで、形骸化を防ぎ常に最新の情報が共有されます。
インシデントの重要度をランク付けする
SaaSビジネスは継続的なサービス提供が前提となるため、属人的な対応を減らし、チーム全体で迅速に問題解決を図る体制を構築することが、サービスの安定稼働と顧客満足度の維持に直結します。
ITIL 4 のインシデント管理プラクティスでも、影響度(impact)と緊急度(urgency)の組み合わせで優先度(priority)を決定することが推奨されており、SaaS の現場でも同じ枠組みが有効に機能します。

インシデント対応の基本事項と判断基準
運用保守において、システム障害や顧客からのエスカレーションといったインシデントが発生した際、初動の遅れは事業に致命的なダメージをもたらします。とくにSaaSはマルチテナント型のアーキテクチャを採用していることが多く、ひとつの障害が全顧客の業務停止を引き起こすリスクを孕んでいます。
具体的な判断ポイントとして、以下の3つの基準を明確化します。
- 影響範囲の特定: 障害が一部の特定のテナント(顧客)のみで発生しているのか、あるいはシステム全体に波及しているのかを即座に切り分けます。
- 重要度のランク付け: サービス提供に致命的な影響を与え、即時対応が必要な「クリティカル」、一部機能が制限されるが回避策が存在する「メジャー」、軽微な表示崩れなどの「マイナー」といった形で、インシデントのレベルを定義します。SLO(サービスレベル目標)に紐づけて「クリティカルは 15 分以内に一次対応」など、MTTR の閾値で運用するとブレません。
- エスカレーションフローの確立: 設定した重要度に応じて、どの段階で事業責任者や開発責任者、あるいはカスタマーサクセスチームに情報共有を行うかをあらかじめ決めておきます。
SLO・SLI・エラーバジェットの具体的な数値設計は、 SLOとは?SLA・SLIとの違いとエラーバジェット運用7つのポイント で SaaS 向けの実例とともに整理しています。
定着を図るための対応訓練
標準化されたフローを実際の開発・運用現場で適用する際、最も注意すべき点は「ルールの形骸化を防ぐこと」です。どれほど詳細なマニュアルを作成しても、実際の緊急時に参照されなければ意味がありません。
現場での定着を図るためには、定期的なインシデント対応訓練を実施し、手順書の有効性を定期的に検証することが効果的です。たとえば、意図的にテスト環境で障害を発生させ、チームがマニュアル通りに復旧できるかを確認する取り組みなどが挙げられます。
また、インシデント対応が完了した後は、事後検証ミーティングを実施します。この際、個人のミスを責めるのではなく、「なぜそのミスが発生し得るシステム・プロセスになっていたのか」という仕組みの課題に焦点を当てることが重要です。心理的安全性の高い環境で根本原因を分析し、得られた教訓をドキュメントとして残すことで、チーム全体の対応力が底上げされます。
ナレッジ共有とドキュメント管理を徹底する
SaaS開発において、属人化を防ぐためのナレッジ共有とドキュメント管理は必須です。特定の運用保守エンジニアしか対応できない状態は、トラブル発生時の復旧遅延やサービス品質の低下を招くリスクとなります。
ドキュメント管理の基本事項は、システム構成図、障害対応フロー、アップデート履歴を常に最新の状態に保つことです。業務体制を見直す際の判断ポイントとなるのは、「メイン担当者が不在の状況でも、他のメンバーがマニュアルを参照して一次対応を完結できるか」という基準です。この基準を満たしていない場合は、速やかに情報の可視化を進める必要があります。
障害対応ドキュメントの必須項目サンプル
マニュアルを実用的に保つため、障害対応の記録には以下の項目をテンプレート化して残すことを推奨します。
- インシデント発生日時と検知方法 (例:2026/5/1 14:00、監視ツールのアラート)
- 影響範囲と事象の詳細 (例:特定機能のAPIエラー発生率が急増)
- 暫定対応と復旧日時 (例:サーバーの再起動を実施し14:15に復旧。MTTR 15 分)
- 根本原因と恒久対応 (例:DBクエリのタイムアウト。次期スプリントでクエリチューニングを実施)
現場で運用する際の注意点は、ドキュメントの更新作業自体が現場の負担にならない仕組みを作ることです。手動による更新を義務付けると形骸化する恐れがあるため、JiraやBacklogなどのチケット管理ツールと連携し、対応完了時に自動で記録を残すなど、業務フローに自然と組み込む工夫が求められます。
継続的な業務改善サイクルを回す
SaaS開発における運用保守を効率化する7つ目のポイントは、継続的な業務改善とナレッジ共有の仕組み化です。日々のトラブル対応やメンテナンス作業を単なるルーティンとして終わらせず、チーム全体の資産へと昇華させるプロセスが求められます。
2026 年現在、運用保守領域では AIOps(AI for IT Operations)の実装が一般化し、アラートのノイズ削減・異常検知・根本原因の自動推定までを AI が担うケースが増えています。RPA や自動化スクリプトに加えて、ログとメトリクスを AI に学習させる選択肢を常にレビューしておくことで、属人化の余地そのものを減らせます。
業務改善を進める際の重要な判断ポイントは、課題の発生頻度と対応工数のバランスです。たとえば、月に何度も発生するパスワードリセットや定型的なアラート対応は、RPAや自動化スクリプトを用いてシステム側で処理させる対象とします。一方で、稀に起きる複雑な障害対応は、詳細な手順書の作成を優先します。このように、費用対効果を見極めて改善のアプローチを選択することが重要です。
現場で運用保守の改善サイクルを回す際の最大の注意点は、作業の属人化を防ぐことです。「特定の担当者しかシステムの復旧手順を知らない」といった状況は、SaaS事業の拡大において深刻なリスクとなります。対応履歴や解決策は、社内ドキュメント(NotionやConfluenceなど)に必ず記録し、チーム内の誰もが迅速に参照できる状態を維持してください。
なお、運用保守の負担はインフラ形態によっても大きく変わります。クラウドとオンプレミスでの体制設計の違いは オンプレミスとクラウドの違いとは?5つの判断基準で最適なシステムを選ぶ方法 で比較しています。
まとめ
SaaSビジネスにおいて、運用保守は単なる「守り」の業務ではなく、顧客の継続利用(LTV)を支える「攻め」の要素です。NetflixやGoogleなどのグローバル企業がSRE(サイト信頼性エンジニアリング)の概念を取り入れ、運用と開発をシームレスに連携させているように、運用保守の質はプロダクトの競争力に直結します。
本記事で解説した以下のポイントを実践し、強固な運用保守基盤を築いてください。
- 運用と保守の役割を明確に分け、責任範囲を定義する(ITIL 4 の 4 つの側面で整理)
- 障害対応フローとエスカレーション体制を構築し、MTTR を最重要 KPI に置く
- 手順化しやすい業務から標準化を進め、属人化を排除する
- インシデントの重要度を SLO に紐づけてランク付けし、初動の迷いをなくす
- チケット管理ツールなどを活用し、ドキュメント更新を仕組み化する
- ポストモーテム(事後検証)を徹底し、根本原因を解決する
- AIOps・自動化も視野に、継続的な業務改善サイクルを回す
これらのプロセスを組織に定着させることで、トラブル発生時の迅速な対応が可能になるだけでなく、開発リソースを新規機能開発や事業価値向上に集中させることができます。安定したサービス提供を通じて、SaaS事業のさらなる成長を実現しましょう。
業務を変えるSaaSと、社内AIシステムを。
B2B 向けの SaaS プロダクトや、企業の業務課題を解決する社内向け AI システムを、企画・設計・開発・運用まで一貫対応。マルチテナント・課金・権限管理といった SaaS 基盤から、LLM を活用した社内ナレッジ検索・ドキュメント生成・業務自動化まで、事業と組織の成長に直結するシステムを構築します。

伊藤翔太
大学卒業後、外資系IT企業にてSaaS製品の法人営業とカスタマーサクセスを経験。その後、国内のBtoBスタートアップに参画し、新規SaaS事業の立ち上げからグロースまでを牽引しました。現在はSaasラボの専属ライターとして、SaaS事業者に役立つ実践的な最新トレンドやノウハウを発信しています。
関連記事

CRMとSFAの違いを比較表で解説|営業改革に最適なツールの選び方
CRMは既存顧客のLTVを伸ばすツール、SFAは新規受注プロセスを標準化するツール。この違いを起点に、自社の課題に合った選び方・連携方法・代表ツール4選・導入失敗を防ぐ3つの対策をまとめました。

要件定義にAIを活用する方法【2026年版】|Claude/ChatGPT/Cursorで使えるプロンプト例7選と失敗しない5つのポイント
「ヒアリングメモから要件を抽出するのに半日かかる」「仕様の抜け漏れで毎回手戻りする」——要件定義はAIで構造的に解消できる工程です。本記事はNTTデータ40%効率化目標・富士通8割工数削減・LayerXのDevin工数1週間削減という2026年の最新事例を出発点に、Claude・ChatGPT・Cursor・Devin・Notion AIで実務にそのまま使える7種のプロンプトと、IPA「テキスト生成AIの導入・運用ガイドライン2024」に沿った5つの失敗回避ポイントをまとめます。

リテンションとは?BtoB SaaSで解約を防ぎLTVを最大化する6つの実践施策【2026年版】
月次解約3.5%・NRRトップ四分位113%・解約理由の25%はオンボーディング起因——。BtoB SaaSのリテンションを左右する2025年最新ベンチマークと、Gainsight CS Index 2025・HiCustomer白書を一次ソースに、オンボーディングからヘルススコア・プロアクティブ支援・KPI・コミュニティ運営まで、CS現場で効く6つの実践施策を解約防止とLTV最大化の観点で具体化しました。

電話対応スクリプトでクレームを防ぐ7つの実践オペレーション【2026年カスハラ義務化対応】
電話対応スクリプトが整備されていないCS現場は、担当者のスキル差がそのままクレーム発生率の差になります。2026年10月のカスハラ対策義務化(改正労働施策総合推進法)を見据え、保留30秒・FCR70〜80%という業界標準KPIに沿った初期ヒアリング・エスカレーション判断・履歴記録までの7つのオペレーションを、SaaS・コールセンター現場に即導入できる形で整理しました。属人化を脱却し、チーム全体の対応品質を底上げしたいCS責任者・オペレーター必読です。

リテンション率とは?SaaS・アプリの計算式・業界目安と改善7施策
リテンション率を「単一の数字」ではなく、計算粒度・業界目安・収益指標(NRR/GRR)・改善施策の 4 階層で運用する方法を整理しました。Mixpanel・Amplitude・Pendo の 2024〜2025 ベンチマークを引きながら、Day 7 と 1 か月の早期離脱を抑える具体策まで体系的に解説します。

リードナーチャリング事例7選|商談化率を2倍にした育成プロセスとMA活用【2026年版】
リードナーチャリングの実在SaaS事例7選を、商談化率2.5倍・問い合わせ10倍・有料移行率30%改善などの具体的な数字とともに紹介。Sansan×Marketo連携、SmartHRのAccount Engagement、freeeのMarketo Engage活用など、一次ソース付きで育成プロセスの全貌を解説します。