SREとは?定義・基本概念・DevOpsとの違いをわかりやすく解説【入門】
SRE(サイト信頼性エンジニアリング)とは何か、その定義と基本概念をわかりやすく解説します。混同されがちなDevOpsとの違い、エラーバジェット・SLI/SLO/SLAの見方、トイル削減まで、SREを初めて学ぶ方のための入門ガイドです。

SRE(Site Reliability Engineering)とは何か――この疑問を持ってこのページに辿り着いた方に向けて、定義から基本概念、DevOpsとの違いまでをわかりやすく解説します。
SREは「サイト信頼性エンジニアリング」とも訳され、Googleが考案したシステム運用の方法論です。ソフトウェアエンジニアリングのアプローチを運用に持ち込むことで、サービスの安定稼働と機能開発のスピードを同時に実現します。本記事では、SREの定義・基本概念・DevOpsとの違いを中心に、エラーバジェット・SLI/SLO/SLA・トイル削減といった重要キーワードも初心者向けに整理します。
信頼性と開発スピードのバランスを保つ
SREとは、Site Reliability Engineeringの略称であり、ソフトウェアエンジニアリングのアプローチを用いてシステムの信頼性を高める実践的な手法です。SaaSビジネスにおいて、システムのダウンタイムは直ちに顧客離れや収益の低下に直結します。そのため、最初のポイントとして最も重要なのは、「システムの信頼性」と「新しい機能の開発スピード」をいかに両立させるかという基本事項の整理にあります。
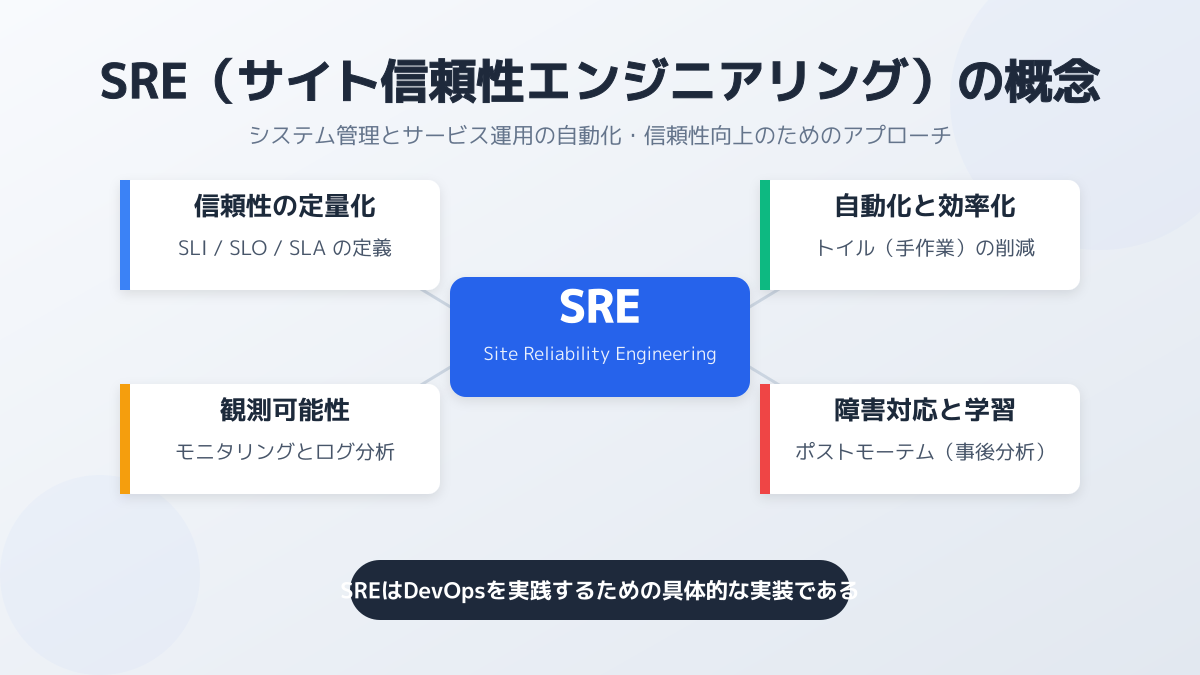
100%の信頼性を目指さないという前提
SREを導入する際、まずは「100%の信頼性を目指さない」という前提を組織全体で共有することが重要です。システムが完全に停止しないことを追求しすぎると、新しい機能のリリースや改善のスピードが著しく低下し、競合優位性を失う原因になります。
そこで、SREでは「エラーバジェット(許容可能な障害の予算)」という概念を用います。あらかじめ一定の障害発生やダウンタイムを許容する予算を設定し、その予算の範囲内で開発チームが自由にリリースを行える仕組みを作ることが要点となります。
現場での判断ポイントと具体的な運用
エラーバジェットを基準とすることで、現場での判断ポイントが客観的かつ明確になります。例えば、バジェットに余裕がある期間は積極的な新機能のリリースを行い、ビジネスの成長を加速させます。一方で、障害が重なりバジェットを使い切ってしまった場合は、新規開発を一時停止してシステムの安定化や技術的負債の解消にリソースを集中させます。
このように、客観的な数値データに基づいて、リリースを進めるべきか、安定化を優先すべきかの行動を決定することが、SaaS運用を成功に導く鍵です。
DevOpsとの違いと役割分担
SaaSビジネスを成長させるためには、システムの信頼性を継続的に高める仕組みが欠かせません。このセクションでは、混同されがちなDevOpsとの違いを整理し、SREがどのように機能するのかを解説します。
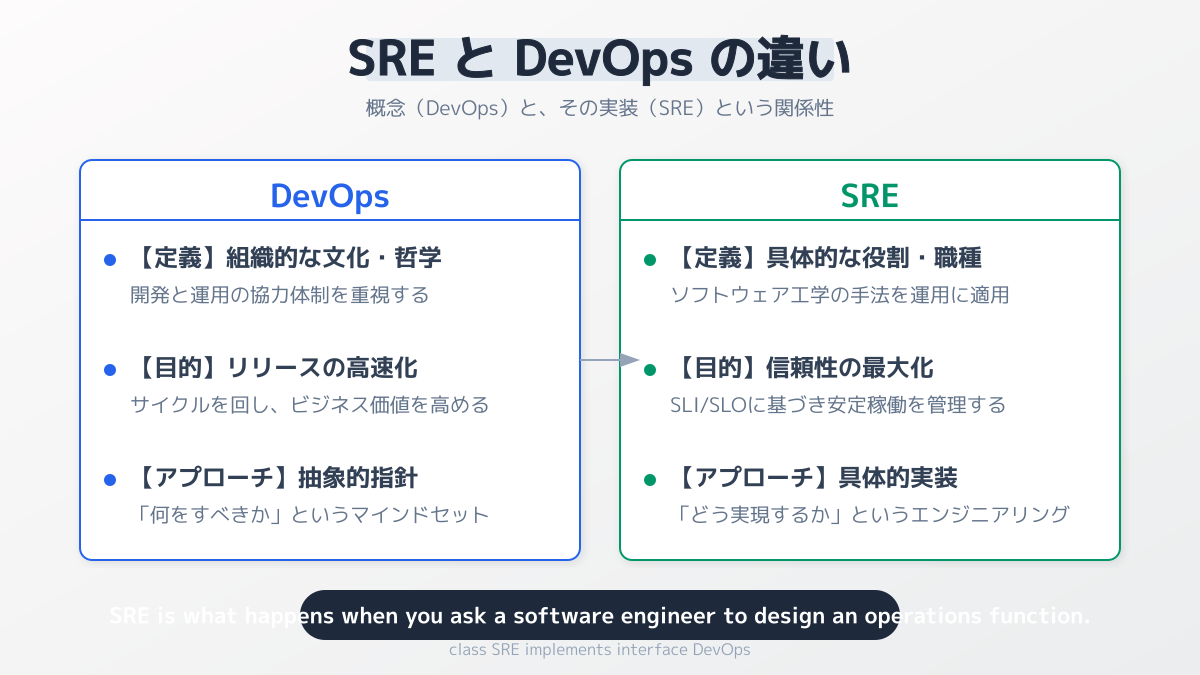
概念と実践のアプローチの違い
システムの安定稼働を理解する上で、DevOpsとの関係性を整理しておく必要があります。DevOpsは、開発チームと運用チームの壁を取り払い、迅速な価値提供を目指す「概念やカルチャー」を指します。一方、SREはソフトウェアエンジニアリングの手法を用いて、その概念を具体的に「実践・実装」するアプローチです。
DevOpsが「何をすべきか」を定義するのに対し、SREは「どのように実現するか」を定義します。以下に、それぞれの役割の違いを比較表で示します。
| 比較項目 | DevOps | SRE |
|---|---|---|
| 定義 | 開発と運用の壁を取り払うための文化・概念 | 信頼性を高めるための具体的なエンジニアリング手法 |
| 目的 | 価値提供(リリース)のスピードアップ | 信頼性と開発スピードのバランス最適化 |
| 指標 | リードタイム、デプロイ頻度など | SLI、SLO、エラーバジェットなど |
| 障害への態度 | 失敗から学び、フィードバックループを回す | ポストモーテム(事後検証)で仕組みの欠陥を特定し再発を防ぐ |
SaaS開発において、両者の違いを正確に把握し、組織内で適切に役割を分担することが、安定したサービス基盤を構築する第一歩となります。SaaS開発全体の流れや構築手順について詳しく知りたい方は、SaaSシステム開発で失敗しない7つのプロセスもあわせて参考にしてください。
【具体例】DevOpsとSREのアプローチの違い
違いをより明確にするため、「新機能のリリース時に障害が発生した」という具体的なシナリオで、両者のアプローチを比較してみましょう。
- DevOpsのアプローチ 開発チームと運用チームが連携して直ちにロールバック(切り戻し)を行い、ダウンタイムを最小限に抑えます。その後、「なぜテストをすり抜けたのか」をプロセス全体から見直し、CI(継続的インテグレーション)のテストコードを拡充して次回のリリースに備えます。
- SREのアプローチ 障害の発生によって「エラーバジェットがどれだけ消費されたか」を計測します。もしバジェットが枯渇していれば、一時的に新機能のリリースを凍結し、システムの安定化を優先する決定を下します。そもそもSREとは、エンジニアが運用課題をソフトウェアの問題として解決する手法です。そのため、手作業での復旧に依存せず、カナリアリリース(少数のユーザーにのみ先行公開する手法)の自動化などを実装し、システム的に影響範囲を限定する仕組みを作ります。
開発と運用の対立を解消する仕組み
従来のIT運用では、「安定」を求める運用チームと「変化」を求める開発チームが衝突しがちでした。DevOpsの理念に基づき、SREでは双方が同じ目標とルールを共有することで、建設的な協力関係を築きます。
エラーバジェットのルールを導入しても、経営層や開発チームがそのルールを遵守しなければ仕組みは機能しません。予算が枯渇した際に「それでも新機能をリリースしたい」という事業側の圧力がかからないよう、あらかじめ事業責任者を含めたステークホルダー全員で、運用ルールを厳格に合意しておくことが重要です。
信頼性を測る3つの指標(SLI/SLO/SLA)
SREを実践する上で、システムの信頼性をどのように定義し、客観的に計測するかは最も重要なテーマの一つです。ここでは、信頼性の基準となる3つの指標について基本事項を整理します。
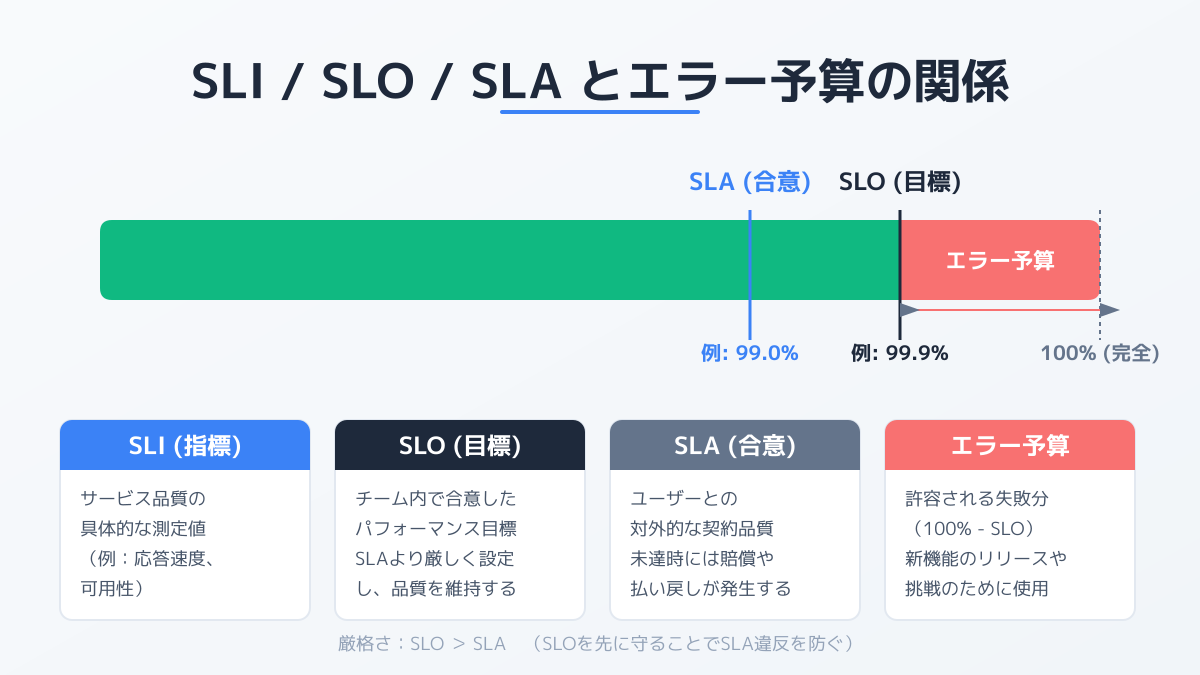
SLI・SLO・SLAの明確な区別
システムの健全性を正確に把握するためには、SLI、SLO、SLAという3つの指標を明確に区別して設定する必要があります。
SLI(Service Level Indicator:サービスレベル指標) は、システムが期待通りに稼働しているかを示す具体的な測定値です。例えば、HTTPリクエストの成功率やデータベースの応答時間などが該当します。ユーザーがサービスを利用する際の体験を直接的に反映する数値を計測することが基本です。
SLO(Service Level Objective:サービスレベル目標) は、測定したSLIに対して設定する内部的な目標値です。「APIリクエストの99.9%が200ミリ秒以内に正常応答する」といった具体的なターゲットを定めます。
SLA(Service Level Agreement:サービスレベル契約) は、サービス提供者と顧客の間で結ばれる外部向けの約束事です。設定した数値を下回った場合、利用料金の返金などのペナルティが発生するため、SLAの基準値は内部目標であるSLOよりも意図的に低く設定し、安全マージンを確保します。
ユーザー視点での指標選定
SLIの選定においては、ユーザーの体感に直結する指標を選ぶ必要があります。サーバーのCPU使用率やメモリ消費量が低く保たれていても、ユーザーの画面表示が遅ければサービスとしての信頼性は低いと判断されます。常にユーザー視点に立って計測ポイントを具体化することが、SREを機能させるための前提となります。
トイル(Toil)の削減と運用自動化
SREを実践する上で、4つ目の重要なポイントとなるのが「トイル(Toil)の削減と自動化」です。手作業による反復的で価値を生まない運用作業を放置すると、システムの規模拡大に伴って運用負荷が限界を迎えます。

トイルとは何か
SREとは、エンジニアが運用業務をソフトウェアの問題として捉え、解決していくアプローチを指します。トイルとは、単なる「嫌な仕事」ではなく、手作業で繰り返され、自動化が可能であり、長期的な価値を生まない運用作業のことです。
Googleが提唱するSREの原則では、エンジニアの作業時間のうち、トイルが占める割合を50%以下に抑えることが推奨されています。残りの時間を、システムの信頼性向上や新しい機能の自動化といった、長期的な価値を生み出すエンジニアリング作業に投資することが基本思想です。
自動化の投資対効果と判断基準
すべての手作業を無条件に自動化すべきではありません。自動化の仕組みを構築・維持するコストが、手作業を続けるコストを上回るケースもあるためです。
判断の基準となるのは、作業の発生頻度と自動化にかかるコストのバランスです。月に1回しか発生せず、手作業でも数分で終わるタスクを何日もかけて自動化するのは投資対効果が見合いません。一方で、1日に何度も発生し、ヒューマンエラーのリスクが高いデプロイ作業やインフラ構築作業は、優先的に自動化すべき対象となります。
インシデント対応とポストモーテム(事後検証)
5つ目のポイントは、障害発生時の迅速な対応と、その後の学びを組織の知見に変えるプロセスです。システムに障害はつきものであり、重要なのは「いかに早く復旧させるか」と「同じ失敗を繰り返さないか」です。
非難なきポストモーテムの徹底
SREにおいて、障害発生後に行う振り返りを「ポストモーテム(事後検証)」と呼びます。ここで最も重要なルールは、「誰がミスをしたか」という個人を非難するのではなく、「なぜシステムがそのミスを防げなかったのか」という仕組みの欠陥に焦点を当てることです。
個人の責任を追及する文化では、エンジニアはミスを隠すようになり、根本的な原因究明が困難になります。非難なき事後検証を徹底することで、心理的安全性が保たれ、システムの堅牢性を高めるための建設的な議論が可能になります。
インシデント対応の標準化
未知の障害に対しては、人間の柔軟な判断が不可欠です。そのため、自動化できる定型作業と、人間の高度な認知能力が必要な作業を明確に切り分け、エンジニアが重要な意思決定に集中できる環境を整えることが求められます。
障害発生時のエスカレーションフローや対応手順(プレイブック)をあらかじめ整備しておくことで、パニックを防ぎ、迅速な復旧を実現できます。
SREを定着させる組織文化の醸成
最後のポイントは、SREのプラクティスを組織に定着させるための文化づくりです。いくら優れたツールや指標を導入しても、それを運用する人々のマインドセットが変わらなければ、SREは形骸化してしまいます。
スモールスタートでの導入
導入初期から完璧な指標を設定しようとすると、かえって現場の負担が増大し、失敗するリスクが高まります。まずは影響範囲の小さいシステムや、一部のチームから最小限の指標を設定して小さく始めることが重要です。
新規事業を立ち上げる際のアプローチと同様に、MVPとはなんの略?ビジネスでの意味と最小限(minimum)の開発で成功する3ステップ を参考に、スモールスタートで検証と改善を繰り返しながら、自社に最適な運用フローを構築していくことが推奨されます。
継続的な改善サイクルの確立
SREの目的は「運用担当者を減らすこと」ではなく、「エンジニアがシステムの信頼性向上や新機能開発など、より価値の高いエンジニアリング業務に注力できる環境を作ること」です。
この目的をチーム全体で共有し、自動化や信頼性向上に投資する工数をあらかじめスプリント計画に組み込んでおくことが重要です。日々の運用作業をコントロール可能な範囲に収めることで、サービスの成長を支える強固な運用体制を構築できます。
まとめ
SaaSビジネスの持続的な成長には、システムの信頼性向上と開発スピードの両立が不可欠であり、その鍵を握るのが SRE (Site Reliability Engineering)です。本記事では、SREの基本概念からDevOpsとの違い、そして信頼性を高めるための6つの実践ポイントを解説しました。
主な要点は以下の通りです。
- 信頼性と開発スピードのバランスをエラーバジェットで管理する。
- DevOpsが文化・哲学であるのに対し、SREはそれを実現する実践的なアプローチである。
- SLI、SLO、SLAを用いて客観的な信頼性指標を設定し、ユーザー視点で計測する。
- トイル(反復的な手作業)を削減し、自動化の投資対効果を見極める。
- 非難なきポストモーテム(事後検証)を通じて、障害を組織の学びに変える。
- スモールスタートで導入し、SREを定着させる組織文化を醸成する。
SREの導入は、一時的な取り組みではなく、継続的な改善サイクルを回すことで真価を発揮します。これらのポイントを組織全体で共有し、実践することで、ユーザーに最高の体験を提供し続ける強固なSaaS運用基盤を構築できるでしょう。
業務を変えるSaaSと、社内AIシステムを。
B2B 向けの SaaS プロダクトや、企業の業務課題を解決する社内向け AI システムを、企画・設計・開発・運用まで一貫対応。マルチテナント・課金・権限管理といった SaaS 基盤から、LLM を活用した社内ナレッジ検索・ドキュメント生成・業務自動化まで、事業と組織の成長に直結するシステムを構築します。

伊藤翔太
大学卒業後、外資系IT企業にてSaaS製品の法人営業とカスタマーサクセスを経験。その後、国内のBtoBスタートアップに参画し、新規SaaS事業の立ち上げからグロースまでを牽引しました。現在はSaasラボの専属ライターとして、SaaS事業者に役立つ実践的な最新トレンドやノウハウを発信しています。
関連記事

要件定義の成果物一覧【サンプル付き】基本設計との違いと手戻りを防ぐ7つのポイント
要件定義フェーズで「何を成果物として作ればよいか」迷っていませんか?本記事では業務要件定義書・機能要件一覧・非機能要件定義書など主要な成果物をサンプル付きで一覧化。「何を決めるか(What)」の要件定義と「どう作るか(How)」の基本設計との役割の違いを明確にし、SaaS開発で手戻りゼロを目指す7つの実践ポイントも解説します。

要件定義書サンプルのシート構成と使い方|Excel活用で抜け漏れを防ぐ7つのポイント
「要件定義書をExcelのどんなシート構成で作ればいいかわからない」「サンプルを流用したのに手戻りが多発した」——本記事は、IPA『非機能要求グレード2018』と『機能要件の合意形成ガイド』に準拠したExcelシート設計の標準形を提示し、項目別チェックリストと7つの運用ポイントで抜け漏れと認識ズレを防ぐ実践ガイドです。

要件定義とは?意味・進め方7ステップと具体例・成果物【IPA/JUAS 一次ソース準拠|2026年版】
「要件定義って結局なにを決めればいいの?」——本記事は要件定義の定義から進め方7ステップ・成果物・要求定義/基本設計との違いまで、IPA非機能要求グレードとJUAS ソフトウェア・メトリクス調査2025の一次ソースで体系的に解説します。プロジェクト担当者がそのまま現場で使える具体例つきの主記事です。

要件定義の進め方5ステップ|手戻りを防ぐMoSCoW分析とIPA非機能要求グレード活用法
「要件定義が甘くてプロジェクトが炎上した」——この失敗を防ぐ鍵は、4ステップで止まらず変更管理まで含めた5ステップで体系化することです。DSDM由来のMoSCoW分析、IPA非機能要求グレード(118項目・3モデル)に準拠した数値化サンプル、勤怠管理システムでの優先順位付け実例まで、現場で使えるノウハウを解説します。

要件定義にAIを活用する方法【2026年版】|Claude/ChatGPT/Cursorで使えるプロンプト例7選と失敗しない5つのポイント
「ヒアリングメモから要件を抽出するのに半日かかる」「仕様の抜け漏れで毎回手戻りする」——要件定義はAIで構造的に解消できる工程です。本記事はNTTデータ40%効率化目標・富士通8割工数削減・LayerXのDevin工数1週間削減という2026年の最新事例を出発点に、Claude・ChatGPT・Cursor・Devin・Notion AIで実務にそのまま使える7種のプロンプトと、IPA「テキスト生成AIの導入・運用ガイドライン2024」に沿った5つの失敗回避ポイントをまとめます。

要件定義書の書き方サンプル|必須6項目とGood例/Bad例・アジャイル対応まで
「要件定義書をどう書けばいいか分からない」「サンプルを真似たのに手戻りが出る」というPdM・SE・事業担当者向けに、必須6項目を Good例 / Bad例 の対比で書ける記載サンプルを提示します。IPA SEC 非機能要求グレード6項目、PMBOK 第7版のスコープ統制、Scrum Guide 2020 に沿ったユーザーストーリー形式、変更要求管理票(CR)まで、現場ですぐ流用できる実践ガイドです。